Что такое алгоритм сортировки?

Алгоритм сортировки — метод, используемый для изменения порядка элементов в структуре данных чтобы облегчить поиск, сравнение и обработку, улучшить производительность и эффективность работы с данными.
Существует множество алгоритмов сортировки, каждый из которых имеет свои плюсы и минусы в зависимости от конкретной задачи и ограничений.
Оценка эффективности алгоритма с использованием нотаций “O-большое”, “Θ-большое” и “Ω-большое”
Wikipedia: «O» большое и «o» малое
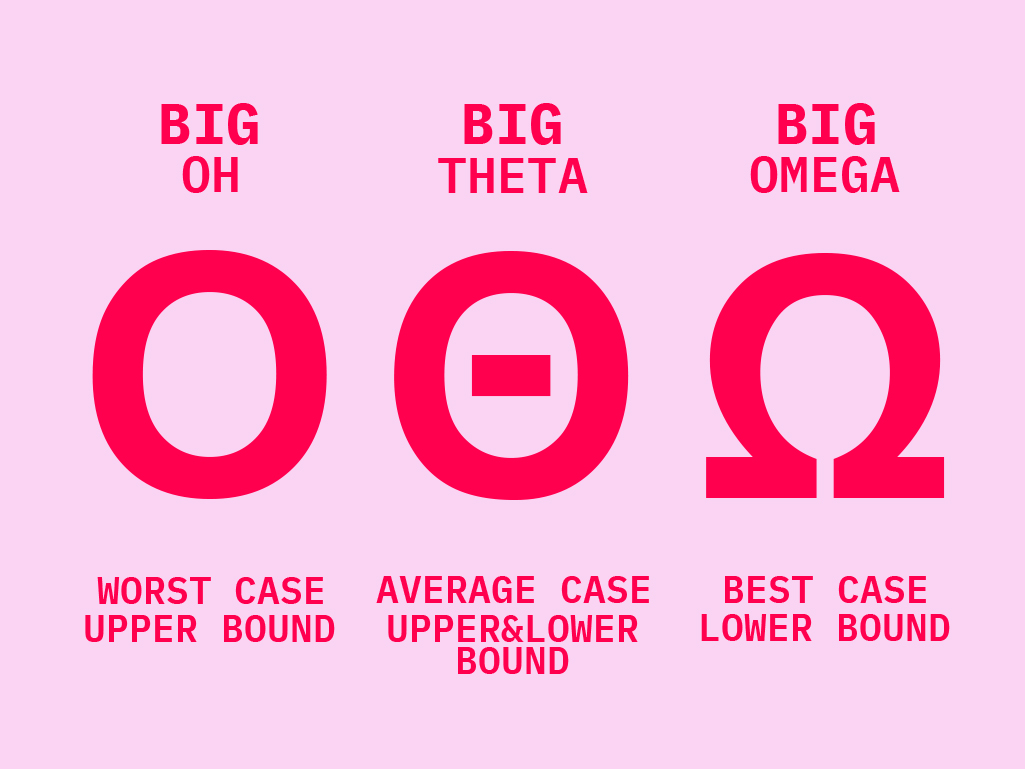
Нотация “O-большое” (Big O)
Худший случай, Worst Case, Нижняя граница
“O-большое” (Big O) нотация – эффективный инструмент в анализе алгоритмов, предназначенный для выражения верхних оценок (наихудших случаев) времени выполнения или использования ресурсов. Формально, если мы можем ограничить время выполнения алгоритма сверху функцией g(n)g(n), мы обозначаем это как O(g(n))O(g(n)).
Нотация “Θ-большое” (Big Θ, Big Theta)
Средний случай, Average Case, Средняя граница
“Θ-большое” (Big Θ) нотация – более точное средство выражения времени выполнения алгоритма, указывающее на точное соответствие между временем выполнения и функцией роста. Если время выполнения алгоритма ограничено как сверху, так и снизу функцией g(n)g(n), мы обозначаем это как Θ(g(n))Θ(g(n)).
Нотация “Ω–большое” (Big Ω, Big Omega)
Лучший случай, Best Case, Верхняя граница
“Ω-большое” (Big Ω) нотация – служит для описания нижних оценок (наилучших случаев) роста времени выполнения или использования ресурсов. Если время выполнения алгоритма ограничено снизу функцией g(n)g(n), мы обозначаем это как Ω(g(n))Ω(g(n)).
Сложность алгоритма
Асимптотическая сложность
Термин “асимптотическая сложность” применяется как к временной (Time complexity), так и к пространственной (Space complexity) сложности алгоритмов. Асимптотическая сложность описывает поведение алгоритма при стремлении размера входных данных к бесконечности.
Вот примеры асимптотических сложностей алгоритма от самой хорошей к самой плохой:
- O(1) – константная сложность
Время выполнения алгоритма постоянно, независимо от размера входных данных.
Объем дополнительной памяти, необходимый для выполнения алгоритма, постоянен и не зависит от размера входных данных. - O(log n) – логарифмическая сложность
Время выполнения алгоритма растет медленнее, чем размер входных данных.
Объем дополнительной памяти растет логарифмически от размера входных данных. - O(n) – линейная сложность
Время выполнения = размеру входных данных.
O(n) указывает на линейную зависимость от размера входных данных в отношении объема дополнительной памяти. - O(n log n) – линейно-логарифмическая сложность
Время выполнения растет быстрее, чем линейное, но медленнее, чем квадратичное. Часто встречается в эффективных сортировках, таких как сортировка слиянием или быстрая сортировка. - O(n2) – квадратичная сложность
Время выполнения пропорционально квадрату размера входных данных. - O(2^n) – экспоненциальная сложность
Время выполнения растет экспоненциально с ростом размера входных данных. - O(n!) – факториальная сложность
Время выполнения растет факториально с ростом размера входных данных, что делает его крайне неэффективным для больших данных.
Временная сложность
Временная сложность (Time Complexity) алгоритма указывается в следующем формате: O(f(n)), где f(n) – функция, описывающая рост времени выполнения алгоритма в зависимости от размера входных данных (n). O(f(n)) описывает верхнюю границу роста времени выполнения алгоритма и указывает, что время выполнения не будет превышать f(n) с учетом некоторых константных множителей.
Время выполнения алгоритма может различаться в зависимости от входных данных. Поэтому указываются следующие случаи временной сложности:
- Худший случай (Worst Case) – максимальное время выполнения алгоритма при наихудших возможных входных данных.
- Лучший случай (Best Case) – минимальное время выполнения алгоритма при наилучших возможных входных данных.
- Средний случай (Average Case) – среднее время выполнения алгоритма при различных случайных входных данных.
Пространственная сложность
Пространственная сложность (Space Complexity) алгоритма измеряет количество дополнительной памяти, которая необходима для выполнения алгоритма, в зависимости от размера входных данных. Она оценивает, сколько дополнительной памяти (в байтах) потребуется для выполнения алгоритма, кроме памяти, необходимой для хранения входных данных. Пространственная сложность может быть важным фактором, особенно при работе с ограниченными ресурсами.
Важно! Временная и пространственная сложности описывают асимптотическое поведение алгоритма и не учитывают константные факторы или малые входные данные.
Что такое устойчивость алгоритма?
Устойчивость алгоритма либо true, либо false. 1 или 0. Stability: 1 или 0.
Устойчивый алгоритм гарантирует сохранение относительного порядка равных элементов, как было во входных данных. Неустойчивый может изменять их порядок.
Устойчивость не является обязательным условием для корректной сортировки, а для ее достижения требуется дополнительная память и время. Тем не менее, это важное и полезное свойство.
Таблица сравнения эффективности алгоритмов сортировок
| O (Worst) | Θ (Average) | Ω (Best) | Space Complexity | Stability | |
| Insertion Sort | O(n2) | Θ(n2) | Ω(n) | O(1) | Yes |
| Selection Sort | O(n2) | Θ(n2) | Ω(n2) | O(1) | No |
| Bubble Sort | O(n2) | Θ(n2) | Ω(n) | O(1) | Yes |
| Gnome Sort | O(n2) | Θ(n2) | Ω(n) | O(1) | Yes |
| Cocktail Sort | O(n2) | Θ(n2) | Ω(n) | O(1) | Yes |
| Heapsort | O(n log n) | Θ(n log n) | Ω(n log n) | O(1) | No |
| Quick Sort | O(n2) | Θ(n log n) | Ω(n log n) | O(log n) | No |
| Merge Sort | O(n log n) | Θ(n log n) | Ω(n log n) | O(n) | Yes |
| Tree Sort | O(n2) | Θ(n log n) | Ω(n log n) | O(n) | No |
| Counting Sort | O(n + k) | Θ(n + k) | Ω(n + k) | O(n + k) | Yes |
| Comb Sort | O(n2) | Θ(n2) | Ω(n log n) | O(1) | No |
| Shellsort | O(n2) | Θ(n1.25) | Ω(n log2 n) | O(1) | No |
| Bucket Sort | O(n + k) | Θ(n) | Ω(n + k) | O(n + k) | Yes |
Самые известные алгоритмы сортировок
Сортировка вставками
Insertion sort
1952, Чарльз Эдвардс (Charles Edwards), “A Method for the Construction of Minimum-Redundancy Codes,” Proceedings of the IRE
Сортировка вставками – простой алгоритм сортировки, который строит отсортированную последовательность путем постепенного включения элементов из исходного массива. Он был разработан в 1950-х годах и является одним из наиболее простых в реализации алгоритмов сортировки.
Основная идея сортировки вставками заключается в следующем:
- Начиная с первого элемента массива, считается, что этот элемент уже находится в отсортированной последовательности.
- Берется следующий элемент и вставляется в правильную позицию в отсортированной части массива, сдвигая при необходимости все элементы, которые больше выбранного элемента.
- Шаг 2 повторяется для всех оставшихся элементов массива, пока не будет достигнут конец массива.
Более формально, алгоритм сортировки вставками можно описать следующим образом:
- Пусть
arr– исходный массив, содержащийnэлементов. - Для каждого элемента
arr[i], начиная с индекса 1 и доn-1, выполняются следующие шаги:
a. Запоминается текущий элементarr[i].
b. Инициализируется переменнаяjсо значениемi-1, которая будет использоваться для поиска правильной позиции для вставки элемента.
c. Покаj >= 0иarr[j]больше запомненного элемента, выполняются следующие действия:
i. Элементarr[j]сдвигается вправо на одну позицию, присваиваяarr[j+1]значениеarr[j].
ii. Уменьшается значениеjна 1.
d. Вставляется запомненный элемент на позициюj+1. - После завершения шага 2 весь массив становится отсортированным.
Сортировка вставками обладает сложностью O(n^2), что делает ее неэффективной для больших массивов. Однако она является устойчивой сортировкой, сохраняющей относительный порядок элементов с одинаковыми значениями, и может быть эффективной для небольших или уже частично отсортированных массивов.
Реализация сортировки вставками на С
Insertion sort Implementation in C
#include <stdio.h>
void insertionSort(int arr[], int n) {
for (int i = 1; i < n; i++) {
int key = arr[i];
int j = i - 1;
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key;
}
}Реализация сортировки вставками на C++
Insertion sort Implementation in C++
#include <vector>
void insertionSort(std::vector<int>& arr) {
if (arr.empty()) {
return;
}
for (size_t i = 1; i < arr.size(); i++) {
int key = arr[i];
size_t j = i - 1;
while (j < arr.size() && arr[j] > key) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key;
}
}
int main() {
std::vector<int> arr = {9, 2, 7, 5, 1, 6, 8, 3, 4};
insertionSort(arr);
for (const auto& num : arr) {
std::cout << num << " ";
}
return (0);
}Эффективность сортировки вставками
Insertion sort Efficiency
| Временная сложность Time Complexity ↓ | |
| Лучший случай Best case → | Ω(n) |
| Худший случай Worst case → | O(n2) |
| Средний случай Average case → | Θ(n2) |
| Пространственная сложность Space Complexity → | O(1) |
| Устойчивость Stability → | Yes |
Сортировка выбором
Selection sort
Сортировка выбором – простой алгоритм сортировки, который на каждой итерации находит минимальный (или максимальный) элемент в не отсортированной части массива и перемещает его в начало (или конец) отсортированной части. Он также относится к семейству алгоритмов сортировки на месте, то есть не требует дополнительной памяти для выполнения сортировки.
Основная идея сортировки выбором заключается в следующем:
- Массив делится на две части: отсортированную (начально пустую) и неотсортированную.
- На каждой итерации находится минимальный (или максимальный) элемент в неотсортированной части и меняется местами с первым элементом неотсортированной части.
- Размер отсортированной части увеличивается на один элемент, а размер неотсортированной части уменьшается на один элемент.
- Шаги 2 и 3 повторяются до тех пор, пока неотсортированная часть массива полностью не исчерпается.
Более формально, алгоритм сортировки выбором можно описать следующим образом:
- Пусть
arr– исходный массив, содержащийnэлементов. - Для каждого индекса
iот 0 доn-1, выполняются следующие шаги:
a. Инициализируется переменнаяminIndexсо значениемi, которая будет хранить индекс минимального элемента в неотсортированной части массива.
b. Для каждого индексаjотi+1доn-1, сравниваются значения элементовarr[j]иarr[minIndex]. Еслиarr[j]меньшеarr[minIndex], обновляется значениеminIndexнаj.
c. Минимальный элементarr[minIndex]меняется местами с элементомarr[i]. - После завершения шага 2 весь массив становится отсортированным.
Сортировка выбором обладает сложностью O(n^2) в худшем, среднем и лучшем случаях. Она неэффективна для больших массивов данных, но может быть полезной для небольших массивов или в случаях, когда требуется минимальное количество перемещений элементов. Она также является неустойчивой сортировкой, то есть не сохраняет относительный порядок элементов с одинаковыми значениями.
Реализация сортировки выбором на C
Selection sort Implementation in C
void selection_sort(int arr[], int n) {
int i, j, min_index, temp;
for (i = 0; i < n-1; i++) {
min_index = i;
for (j = i+1; j < n; j++)
if (arr[j] < arr[min_index])
min_index = j;
temp = arr[min_index];
arr[min_index] = arr[i];
arr[i] = temp;
}
}Реализация сортировки выбором на C++
Selection sort Implementation in C++
#include <iostream>
void selectionSort(int arr[], int n) {
for (int i = 0; i < n - 1; i++) {
int min_index = i;
for (int j = i + 1; j < n; j++) {
if (arr[j] < arr[min_index]) {
min_index = j;
}
}
std::swap(arr[i], arr[min_index]);
}
}Эффективность сортировки выбором
Selection sort Efficiency
| Временная сложность Time Complexity ↓ | |
| Лучший случай Best case → | Ω(n2) |
| Худший случай Worst case → | O(n2) |
| Средний случай Average case → | Θ(n2) |
| Пространственная сложность Space Complexity→ | O(1) |
| Устойчивость Stability → | No |
Сортировка пузырьком
Bubble sort
Сортировка пузырьком (Bubble Sort) – один из наиболее простых алгоритмов сортировки. Он получил свое название из-за характерного “поднимающегося” движения элементов, когда большие элементы “поднимаются” к верхней части массива, как пузырьки воды в газировке. Этот алгоритм был разработан в начале 20-го века и является одним из самых интуитивных способов сортировки массивов.
Реализация алгоритма сортировки пузырьком на C
Bubble sort Implementation in C
void bubbleSort(int arr[], int size) {
for (int i = 0; i < size - 1; ++i) {
for (int j = 0; j < size - i - 1; ++j) {
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}Реализация алгоритма сортировки пузырьком на C++
Bubble sort Implementation in C++
#include <iostream>
void bubbleSort(int arr[], int n) {
for (int i = 0; i < n - 1; i++) {
for (int j = 0; j < n - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
std::swap(arr[j], arr[j + 1]);
}
}
}
}Эффективность сортировки пузырьком
Bubble sort Efficiency
| Временная сложность Time Complexity ↓ | |
| Лучший случай Best case → | Ω(n) |
| Худший случай Worst case → | O(n2) |
| Средний случай Average case → | Θ(n2) |
| Пространственная сложность Space Complexity → | O(1) |
| Устойчивость Stability → | Yes |
Гномья сортировка
Gnome sort
2000, Hamid Sarbazi-Azad, “The Art of Sorting” by Hamid Sarbazi-Azad
Гномья сортировка — простой алгоритм сортировки, похожий на сортировку вставками. Он был назван «гномьей» из-за своего поведения: он перемещается по массиву, подобно гному, и проверяет, нужно ли поменять два соседних элемента местами. Если элементы находятся в правильном порядке, гном продвигается вперед, а если элементы находятся в неправильном порядке, гном меняет их местами и двигается назад. Алгоритм продолжает перемещаться по массиву, пока не достигнет конца.
procedure gnomeSort(a[]):
pos := 0
while pos < length(a):
if (pos == 0 or a[pos] >= a[pos-1]):
pos := pos + 1
else:
swap a[pos] and a[pos-1]
pos := pos - 1Реализация алгоритма гномьей сортировки на C
Gnome sort Implementation in C
#include <stdio.h>
void gnomeSort(int arr[], int n) {
int index = 0;
while (index < n) {
if (index == 0 || arr[index] >= arr[index - 1]) {
index++;
} else {
int temp = arr[index];
arr[index] = arr[index - 1];
arr[index - 1] = temp;
index--;
}
}
}Реализация алгоритма гномьей сортировки на C
Gnome sort Implementation in C++
void gnomeSort(std::vector<int>& arr) {
int n = arr.size();
int index = 0;
while (index < n) {
if (index == 0)
index++;
if (arr[index] >= arr[index - 1])
index++;
else {
std::swap(arr[index], arr[index - 1]);
index--;
}
}
}Эффективность гномьей сортировки
Gnome sort Efficiency
| Временная сложность Time Complexity ↓ | |
| Лучший случай Best case → | Ω(n) |
| Худший случай Worst case → | O(n2) |
| Средний случай Average case → | Θ(n2) |
| Пространственная сложность Space Complexity → | O(1) |
| Устойчивость Stability → | Yes |
Сортировка перемешиванием
Cocktail sort
2000, Hamid Sarbazi-Azad, “The Art of Sorting” by Hamid Sarbazi-Azad
Сортировка перемешиванием (Cocktail Sort) – усовершенствованный вариант сортировки пузырьком. Алгоритм был разработан, чтобы устранить недостатки сортировки пузырьком и уменьшить количество проходов по массиву. В сортировке перемешиванием элементы массива сравниваются и перемещаются в обоих направлениях (от начала к концу и обратно).
Реализация алгоритма сортировки перемешиванием на C
Cocktail sort Implementation in C
#include <stdio.h>
void cocktailSort(int array[], int n) {
int left = 0;
int right = n - 1;
int swapped = 0;
while (left < right) {
for (int i = left; i < right; ++i) {
if (array[i] > array[i + 1]) {
int temp = array[i];
array[i] = array[i + 1];
array[i + 1] = temp;
swapped = 1;
}
}
right--;
for (int i = right; i > left; --i) {
if (array[i - 1] > array[i]) {
int temp = array[i];
array[i] = array[i - 1];
array[i - 1] = temp;
swapped = 1;
}
}
left++;
if (!swapped) {
break;
}
}
}Реализация алгоритма сортировки перемешиванием на C
Cocktail sort Implementation in C
#include <iostream>
void cocktailSort(int arr[], int n) {
bool swapped = true;
int start = 0;
int end = n - 1;
while (swapped) {
swapped = false;
for (int i = start; i < end; i++) {
if (arr[i] > arr[i + 1]) {
std::swap(arr[i], arr[i + 1]);
swapped = true;
}
}
if (!swapped) {
break;
end--;
for (int i = end; i > start; i--) {
if (arr[i] < arr[i - 1]) {
std::swap(arr[i], arr[i - 1]);
swapped = true;
}
}
start++;
}
}Эффективность сортирвки перемешиванием
Coctail sort Efficiency
| Временная сложность Time Complexity ↓ | |
| Лучший случай Best case → | Ω(n) |
| Худший случай Worst case → | O(n2) |
| Средний случай Average case → | Θ(n2) |
| Пространственная сложность Space Complexity → | O(1) |
| Устойчивость Stability → | Yes |
Пирамидальная сортировка
Heapsort
1964, B. R. Heap (Разработана на основе работы Р. В. Флойда), “Programming Languages: History and Fundamentals”
Пирамидальная сортировка – алгоритм сортировки, основанный на структуре данных под названием “куча” (heap). Он был разработан в 1960-х годах и является несравненно эффективным, особенно для больших массивов данных.
Основная идея пирамидальной сортировки заключается в следующем:
- Сначала строится “пирамида” из исходного массива. Пирамида представляет собой специальную структуру данных, удовлетворяющую условию “родительский элемент всегда меньше или равен своим дочерним элементам”. Построение пирамиды выполняется поэтапно, начиная с последнего родительского элемента и заканчивая корневым элементом массива.
- После построения пирамиды максимальный элемент (корень пирамиды) находится в начале массива. Он меняется местами с последним элементом массива, который считается отсортированным.
- Размер пирамиды уменьшается на 1, и выполняется операция “просеивания вниз” (sift down) для нового корня пирамиды. Это означает, что элементы перестраиваются таким образом, чтобы снова удовлетворять условию пирамиды.
- Шаги 2 и 3 повторяются до тех пор, пока весь массив не будет отсортирован.
Более формально, алгоритм пирамидальной сортировки можно описать следующим образом:
- Построение пирамиды:
a. Перебираются все родительские элементы массива, начиная с последнего и до первого.
b. Для каждого родительского элемента выполняется операция “просеивания вниз”, чтобы удовлетворить условие пирамиды. - Сортировка:
a. Пока размер пирамиды больше 1, выполняются следующие шаги:
i. Меняются местами корень пирамиды (максимальный элемент) с последним элементом массива.
ii. Уменьшается размер пирамиды на 1.
iii. Выполняется операция “просеивания вниз” для нового корня пирамиды.
b. После завершения шага 2 массив будет полностью отсортирован в порядке возрастания.
Реализация пирамидальной сортировки на C
Heapsort Implementation in C
#include <stdio.h>
void swap(int* a, int* b) {
int temp = *a;
*a = *b;
*b = temp;
}
void heapify(int arr[], unsigned int n, unsigned int i) {
unsigned int largest = i;
unsigned int left = 2 * i + 1;
unsigned int right = 2 * i + 2;
if (left < n && arr[left] > arr[largest]) {
largest = left;
}
if (right < n && arr[right] > arr[largest]) {
largest = right;
}
if (largest != i) {
swap(&arr[i], &arr[largest]);
heapify(arr, n, largest);
}
}
void heapSort(int arr[], unsigned int n) {
if (arr == NULL || n <= 1) {
return;
}
for (int i = n / 2 - 1; i >= 0; i--) {
heapify(arr, n, i);
}
for (int i = n - 1; i > 0; i--) {
if (arr[0] > arr[i]) {
swap(&arr[0], &arr[i]);
heapify(arr, i, 0);
}
}
}
int main() {
int arr[] = {9, 2, 7, 5, 1, 6, 8, 3, 4};
unsigned int n = sizeof(arr) / sizeof(arr[0]);
heapSort(arr, n);
printf("Sorted array: ");
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
return (0);
}Реализация пирамидальной сортировки на C++
Heapsort Implementation in C++
#include <iostream>
#include <algorithm>
void heapify(int arr[], int n, int i) {
int largest = i;
int left = 2 * i + 1;
int right = 2 * i + 2;
if (left < n && arr[left] > arr[largest]) {
largest = left;
}
if (right < n && arr[right] > arr[largest]) {
largest = right;
}
if (largest != i) {
std::swap(arr[i], arr[largest]);
heapify(arr, n, largest);
}
}
void heapSort(int arr[], int n) {
for (int i = n / 2 - 1; i >= 0; i--) {
heapify(arr, n, i);
}
for (int i = n - 1; i > 0; i--) {
std::swap(arr[0], arr[i]);
heapify(arr, i, 0);
}
}Эффективность пирамидальной сортировки
Heapsort sort Efficiency
| Временная сложность Time Complexity ↓ | |
| Лучший случай Best case → | Ω(n log n) |
| Худший случай Worst case → | O(n log n) |
| Средний случай Average case → | Θ(n log n) |
| Пространственная сложность Space Complexity → | O(1) |
| Устойчивость Stability → | No |
Быстрая сортировка
Quick sort
1961, Тони Хоар (Tony Hoare), “Algorithm 63: Quicksort” в Communications of the ACM
Быстрая сортировка (Quick Sort) – эффективный алгоритм сортировки, основанный на принципе “разделяй и властвуй”. Он работает путем выбора опорного элемента и разделения массива на две подгруппы: элементы, меньшие опорного, и элементы, большие опорного. Затем каждая из этих подгрупп сортируется рекурсивно. Быстрая сортировка обычно применяется для сортировки больших наборов данных, и в среднем случае имеет сложность O(n log n).
Реализация алгоритма быстрой сортировки
Quick sort Implementation in C
#include <iostream>
void swap(int &a, int &b) {
int temp = a;
a = b;
b = temp;
}
int partition(int arr[], int low, int high) {
int pivot = arr[high];
int i = (low - 1);
for (int j = low; j <= high - 1; j++) {
if (arr[j] < pivot) {
i++;
swap(arr[i], arr[j]);
}
}
swap(arr[i + 1], arr[high]);
return (i + 1);
}
void quickSort(int arr[], int low, int high) {
if (low < high) {
int pivotIndex = partition(arr, low, high);
quickSort(arr, low, pivotIndex - 1);
quickSort(arr, pivotIndex + 1, high);
}
}Реализация алгоритма быстрой сортировки на C++
Quick sort Implementation in C++
template<class T>
void quickSortR(T* a, long N) {
long i = 0, j = N-1;
T temp, p;
p = a[ N>>1 ];
do {
while ( a[i] < p ) i++;
while ( a[j] > p ) j--;
if (i <= j) {
temp = a[i]; a[i] = a[j]; a[j] = temp;
i++; j--;
}
} while ( i<=j );
if ( j > 0 ) quickSortR(a, j);
if ( N > i ) quickSortR(a+i, N-i);
}Эффективность быстрой сортировки
Quick sort Efficiency
| Временная сложность Time Complexity ↓ | |
| Лучший случай Best case → | Ω(n log n) |
| Худший случай Worst case → | O(n2) |
| Средний случай Average case → | Θ(n log n) |
| Пространственная сложность Space Complexity → | O(log n) |
| Устойчивость Stability → | No |
Сортировка слиянием
Merge sort
1945, Джон фон Нейман (John von Neumann), Описана в “First Draft of a Report on the EDVAC”
Сортировка слиянием (Merge Sort) – эффективный алгоритм сортировки, который использует принцип “разделяй и властвуй”. Этот метод сортировки был разработан Джоном фон Нейманом в 1945 году и считается одним из фундаментальных алгоритмов в информатике. Он отличается от других алгоритмов тем, что работает с рекурсией и допускает эффективную сортировку как небольших, так и очень больших наборов данных.
Реализация сортировки слиянием на C
Merge sort Implementation in C
void mergeSort(int arr[], int l, int r) {
if (l < r) {
int m = l + (r - l) / 2;
mergeSort(arr, l, m);
mergeSort(arr, m + 1, r);
merge(arr, l, m, r);
}
}
void merge(int arr[], int l, int m, int r) {
int i, j, k;
int n1 = m - l + 1;
int n2 = r - m;
int L[n1], R[n2];
for (i = 0; i < n1; i++)
L[i] = arr[l + i];
for (j = 0; j < n2; j++)
R[j] = arr[m + 1 + j];
i = 0;
j = 0;
k = l;
while (i < n1 && j < n2) {
if (L[i] <= R[j]) {
arr[k] = L[i];
i++;
} else {
arr[k] = R[j];
j++;
}
k++;
}
while (i < n1) {
arr[k] = L[i];
i++;
k++;
}
while (j < n2) {
arr[k] = R[j];
j++;
k++;
}
}
mergeSort(arr, 0, size - 1);Реализация сортировки слиянием на C++
Merge sort Implementation in C++
#include <iostream>
void merge(int arr[], int left, int middle, int right) {
int n1 = middle - left + 1;
int n2 = right - middle;
int L[n1], R[n2];
for (int i = 0; i < n1; i++) {
L[i] = arr[left + i];
}
for (int i = 0; i < n2; i++) {
R[i] = arr[middle + 1 + i];
}
int i = 0, j = 0, k = left;
while (i < n1 && j < n2) {
if (L[i] <= R[j]) {
arr[k] = L[i];
i++;
} else {
arr[k] = R[j];
j++;
}
k++;
}
while (i < n1) {
arr[k] = L[i];
i++;
k++;
}
while (j < n2) {
arr[k] = R[j];
j++;
k++;
}
}
void mergeSort(int arr[], int left, int right) {
if (left < right) {
int middle = left + (right - left) / 2;
mergeSort(arr, left, middle);
mergeSort(arr, middle + 1, right);
merge(arr, left, middle, right);
}
}Эффективность сортировки слиянием
Merge sort Efficiency
| Временная сложность Time Complexity ↓ | |
| Лучший случай Best case → | Ω(n log n) |
| Худший случай Worst case → | O(n log n) |
| Средний случай Average case → | Θ(n log n) |
| Пространственная сложность Space Complexity → | O(n) |
| Устойчивость Stability → | Yes |
Сортировка с помощью двоичного дерева
Tree sort
1957, R. W. Floyd, “Algorithms for Coding”
Сортировка с помощью двоичного дерева (Tree Sort) использует структуру двоичного дерева для упорядочивания элементов. Принцип работы заключается в создании дерева, в котором меньшие элементы находятся в левом поддереве, а большие – в правом. Для сортировки массива, элементы вставляются в дерево, затем производится обход дерева в порядке возрастания, что дает отсортированный результат. Метод применяется в тех случаях, когда нужно отсортировать большие наборы данных, и при этом обеспечивает устойчивость сортировки.
Реализация алгоритма сортировки с помощью двоичного дерева на C
Tree sort Implementation in C
#include <stdio.h>
#include <stdlib.h>
struct Node {
int data;
struct Node* left;
struct Node* right;
};
struct Node* createNode(int data) {
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->data = data;
newNode->left = NULL;
newNode->right = NULL;
return newNode;
}
struct Node* insert(struct Node* root, int data) {
if (root == NULL) {
return createNode(data);
}
if (data < root->data) {
root->left = insert(root->left, data);
} else if (data > root->data) {
root->right = insert(root->right, data);
}
return root;
}
void inorder(struct Node* root) {
if (root != NULL) {
inorder(root->left);
printf("%d ", root->data);
inorder(root->right);
}
}Реализация алгоритма сортировки с помощью двоичного дерева на C++
Tree sort Implementation in C++
#include <iostream>
// Структура для представления узла в двоичном дереве
struct Node {
int data;
Node* left;
Node* right;
Node(int value) {
data = value;
left = nullptr;
right = nullptr;
}
};
// Вспомогательная функция для вставки узла в двоичное дерево
Node* insert(Node* root, int value) {
if (root == nullptr) {
return new Node(value);
}
if (value < root->data) {
root->left = insert(root->left, value);
} else {
root->right = insert(root->right, value);
}
return root;
}
// Рекурсивная функция для обхода двоичного дерева в порядке возрастания
void inOrderTraversal(Node* root) {
if (root != nullptr) {
inOrderTraversal(root->left);
std::cout << root->data << " ";
inOrderTraversal(root->right);
}
}
// Функция для сортировки с помощью двоичного дерева
void treeSort(int arr[], int n) {
Node* root = nullptr;
// Вставляем каждый элемент массива в двоичное дерево
for (int i = 0; i < n; i++) {
root = insert(root, arr[i]);
}
// Обходим дерево в порядке возрастания и перезаписываем элементы в массив
int index = 0;
inOrderTraversal(root, arr, index);
}
int main() {
int arr[] = {7, 2, 5, 1, 9, 3};
int n = sizeof(arr) / sizeof(arr[0]);
std::cout << "Исходный массив: ";
for (int i = 0; i < n; i++) {
std::cout << arr[i] << " ";
}
std::cout << std::endl;
treeSort(arr, n);
std::cout << "Отсортированный массив: ";
for (int i = 0; i < n; i++) {
std::cout << arr[i] << " ";
}
std::cout << std::endl;
return (0);
}Эффективность сортировки с помощью двоичного дерева
Tree sort Efficiency
| Временная сложность Time Complexity ↓ | |
| Лучший случай Best case → | Ω(n log n) |
| Худший случай Worst case → | O(n2) |
| Средний случай Average case → | Θ(n log n) |
| Пространственная сложность Space Complexity → | O(n) |
| Устойчивость Stability → | No |
Сортировка подсчётом
Counting sort
1954, Harold H. Seward, “Electronic Computers”
История сортировки подсчетом начинается в 1954 году с публикации американского математика и информатика Харольда Хора (Harold H. Seward). Однако алгоритм был формально описан и опубликован в 1955 году в работе “Methods of Programming and Simulated Training” (Методы программирования и имитационного обучения) Харольда Хора.
Реализация алгоритма сортировки подсчётом на C
Counting sort Implementation in C
void countingSort(int* array, int n, int k) {
int* c = (int*)malloc((k+1) * sizeof(*array));
memset(c, 0, sizeof(*array)*(k+1));
for (int i = 0; i < n; ++i) {
++c[array[i]];
}
int b = 0;
for (int i = 0; i < k+1; ++i){
for (int j = 0; j < c[i]; ++j) {
array[b++] = i;
}
}
free(c);
}Реализация алгоритма сортировки подсчётом на C++
Counting sort Implementation in C++
#include <vector>
#include <type_traits>
#include <algorithm>
template <typename std::enable_if_t<std::is_integral_v<T>, T>>
void countingSort(std::vector<T>& array) {
T max = std::max_element(array.begin(), array.end());
auto count = std::vector<T>(max+1, T(0));
for (T elem : array)
++count[elem];
T b = 0;
for (size_t i = 0; i < max+1; ++i) {
for (T j = 0; j < count[i]; ++j) {
array[b++] = i;
}
}
}Эффективность сортировки подсчетом
Counting sort Efficiency
| Временная сложность Time Complexity ↓ | |
| Лучший случай Best case → | Ω(n + k) |
| Худший случай Worst case → | O(n + k) |
| Средний случай Average case → | Θ(n + k) |
| Пространственная сложность Space Complexity → | O(n + k) |
| Устойчивость Stability → | Yes |
Сортировка расчёской
Comb sort
1980, Владимир Добос (Vladimír Dósa), “Methods and Tools for Computer Technology”
Сортировка расчёской (Comb sort) – улучшенная версия сортировки пузырьком, которая позволяет более эффективно перемещать элементы в массиве. Она была разработана в 1980-х годах Ричардом Шелдоном.
Основная идея сортировки расчёской заключается в следующем:
- Похоже на сортировку пузырьком, сортировка расчёской также сравнивает пары соседних элементов и меняет их местами, если они находятся в неправильном порядке.
- Однако вместо того, чтобы сравнивать соседние элементы постоянно, сортировка расчёской использует большую “шаговую” дистанцию для сравнения элементов. Начальная шаговая дистанция обычно равна длине массива.
- На каждой итерации элементы сравниваются на шаговой дистанции, и если необходимо, меняются местами.
- После завершения итерации шаговая дистанция уменьшается с помощью фактора уменьшения (обычно примерно равного 1.3).
- Процесс повторяется до тех пор, пока шаговая дистанция не станет равной 1.
- В конце сортировки выполняется последняя итерация с шаговой дистанцией 1, чтобы убедиться, что массив полностью отсортирован.
Более формально, алгоритм сортировки расчёской можно описать следующим образом:
- Пусть
arr– исходный массив, содержащийnэлементов. - Инициализируется шаговая дистанция
gapсо значениемn. - Создается флаг
swappedсо значениемtrue, который указывает на то, что произошел обмен элементов на текущей итерации. - Пока
gapбольше 1 илиswappedравноtrue, выполняются следующие шаги:
a. Устанавливается значениеgapравнымgap / 1.3(или другому фактору уменьшения).
b. Еслиgapстановится меньше 1, устанавливается значениеgapравным 1.
c. Устанавливается значениеswappedравнымfalse.
d. Для каждого индексаiот 0 доn - gap, выполняются следующие действия:
i. Сравниваются элементыarr[i]иarr[i + gap].
ii. Еслиarr[i]большеarr[i + gap], элементы меняются местами и устанавливается значениеswappedравнымtrue. - После завершения шага 4 весь массив становится отсортированным.
Сортировка расчёской имеет сложность O(n^2) в худшем случае, но может быть значительно быстрее сортировки пузырьком на практике, особенно для массивов с большим количеством обратно упорядоченных элементов. Она также является сортировкой на месте, что означает, что она не требует дополнительной памяти для выполнения сортировки.
Реализация алгоритма сортировки расчёской на C
Comb sort Implementation in C
#include <stdio.h>
void swap(int* a, int* b) {
int temp = *a;
*a = *b;
*b = temp;
}
void combSort(int arr[], int n) {
int gap = n;
float shrink = 1.3;
int swapped = 1;
while (gap > 1 || swapped) {
gap = (int)(gap / shrink);
if (gap < 1) {
gap = 1;
}
swapped = 0;
for (int i = 0; i < n - gap; i++) {
if (arr[i] > arr[i + gap]) {
swap(&arr[i], &arr[i + gap]);
swapped = 1;
}
}
}
}Реализация алгоритма сортировки расчёской на C++
Comb sort Implementation in C++
#include <iostream>
#include <vector>
using namespace std;
void swap(int& a, int& b) {
int temp = a;
a = b;
b = temp;
}
void combSort(vector<int>& arr) {
int n = arr.size();
int gap = n;
float shrink = 1.3;
bool swapped = true;
while (gap > 1 || swapped) {
gap = static_cast<int>(gap / shrink);
if (gap < 1) {
gap = 1;
}
swapped = false;
for (int i = 0; i < n - gap; i++) {
if (arr[i] > arr[i + gap]) {
swap(arr[i], arr[i + gap]);
swapped = true;
}
}
}
}Эффективность сортировки расчёской
Comb sort Efficiency
| Временная сложность Time Complexity ↓ | |
| Лучший случай Best case → | Ω(n log n) |
| Худший случай Worst case → | O(n2) |
| Средний случай Average case → | Θ(n2) |
| Пространственная сложность Space Complexity → | O(1) |
| Устойчивость Stability → | No |
Сортировка Шелла
Shellsort
1959, Дональд Шелл (Donald Shell), “A High-Speed Sorting Procedure”
Сортировка Шелла – улучшенный алгоритм сортировки вставками, который использует последовательность инкрементов для эффективной сортировки элементов в массиве. Он получил свое название от своего создателя, Дональда Шелла.
Реализация алгоритма сортировки Шелла на C
Shellsort Implementation in C
#include <stdio.h>
void shellSort(int arr[], int n) {
int gap, i, j, temp;
for (gap = n / 2; gap > 0; gap /= 2) {
for (i = gap; i < n; i++) {
temp = arr[i];
for (j = i; j >= gap && arr[j - gap] > temp; j -= gap) {
arr[j] = arr[j - gap];
}
arr[j] = temp;
}
}
}Реализация алгоритма сортировки Шелла на C++
Shellsort Implementation in C++
#include <iostream>
void shellSort(int arr[], int n) {
for (int gap = n / 2; gap > 0; gap /= 2) {
for (int i = gap; i < n; i++) {
int temp = arr[i];
int j;
for (j = i; j >= gap && arr[j - gap] > temp; j -= gap) {
arr[j] = arr[j - gap];
}
arr[j] = temp;
}
}
}Эффективность сортировки Шелла
Shellsort Efficiency
| Временная сложность Time Complexity ↓ | |
| Лучший случай Best case → | Ω(n log2 n) |
| Худший случай Worst case → | O(n2) |
| Средний случай Average case → | Θ(n1.25) |
| Пространственная сложность Space Complexity → | O(1) |
| Устойчивость Stability → | No |
Блочная сортировка
Bucket sort
1962, Янис Леонис (Janis Lejnieks), “Digital Computer Programming” by Yale University
Сортировка с использованием корзин (Bucket sort) – алгоритм сортировки, который разбивает входной массив на равные интервалы (корзины), распределяет элементы массива по соответствующим корзинам, затем отдельно сортирует каждую корзину (обычно с использованием другого сортировочного алгоритма или рекурсивно применяя сортировку с использованием корзин).
Реализация алгоритма блочной сортировки на C
Bucket sort Implementation in C
#include <stdio.h>
#include <stdlib.h>
void bucketSort(int arr[], int n) {
int max = arr[0];
for (int i = 1; i < n; i++) {
if (arr[i] > max) {
max = arr[i];
}
}
int bucket[max + 1];
for (int i = 0; i <= max; i++) {
bucket[i] = 0;
}
for (int i = 0; i < n; i++) {
bucket[arr[i]]++;
}
int index = 0;
for (int i = 0; i <= max; i++) {
while (bucket[i] > 0) {
arr[index] = i;
index++;
bucket[i]--;
}
}
}Реализация алгоритма блочной сортировки на C++
Bucket sort Implementation in C++
#include <iostream>
#include <vector>
#include <algorithm>
#include <cmath>
void insertionSort(std::vector<int>& bucket) {
for (int i = 1; i < bucket.size(); ++i) {
int key = bucket[i];
int j = i - 1;
while (j >= 0 && bucket[j] > key) {
bucket[j + 1] = bucket[j];
j--;
}
bucket[j + 1] = key;
}
}
void bucketSort(std::vector<int>& arr) {
int n = arr.size();
std::vector<std::vector<int>> buckets(n);
for (int i = 0; i < n; ++i) {
int bucketIndex = n * arr[i];
buckets[bucketIndex].push_back(arr[i]);
}
for (int i = 0; i < n; ++i) {
insertionSort(buckets[i]);
}
int index = 0;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < buckets[i].size(); ++j) {
arr[index++] = buckets[i][j];
}
}
}
int main() {
std::vector<int> arr = {0.42, 0.32, 0.85, 0.04, 0.69, 0.11, 0.78};
bucketSort(arr);
for (int i = 0; i < arr.size(); ++i) {
std::cout << arr[i] << " ";
}
std::cout << std::endl;
return (0);
}Эффективность блочной сортировки
Bucket sort Efficiency
| Временная сложность Time Complexity ↓ | |
| Лучший случай Best case → | Ω(n + k) |
| Худший случай Worst case → | O(n2) |
| Средний случай Average case → | Θ(n) |
| Пространственная сложность Space Complexity → | O(n + k) |
| Устойчивость Stability → | Yes |


